Gradients or Mutations? Musings on Genetic Algorithms and Deep Learning (v0)
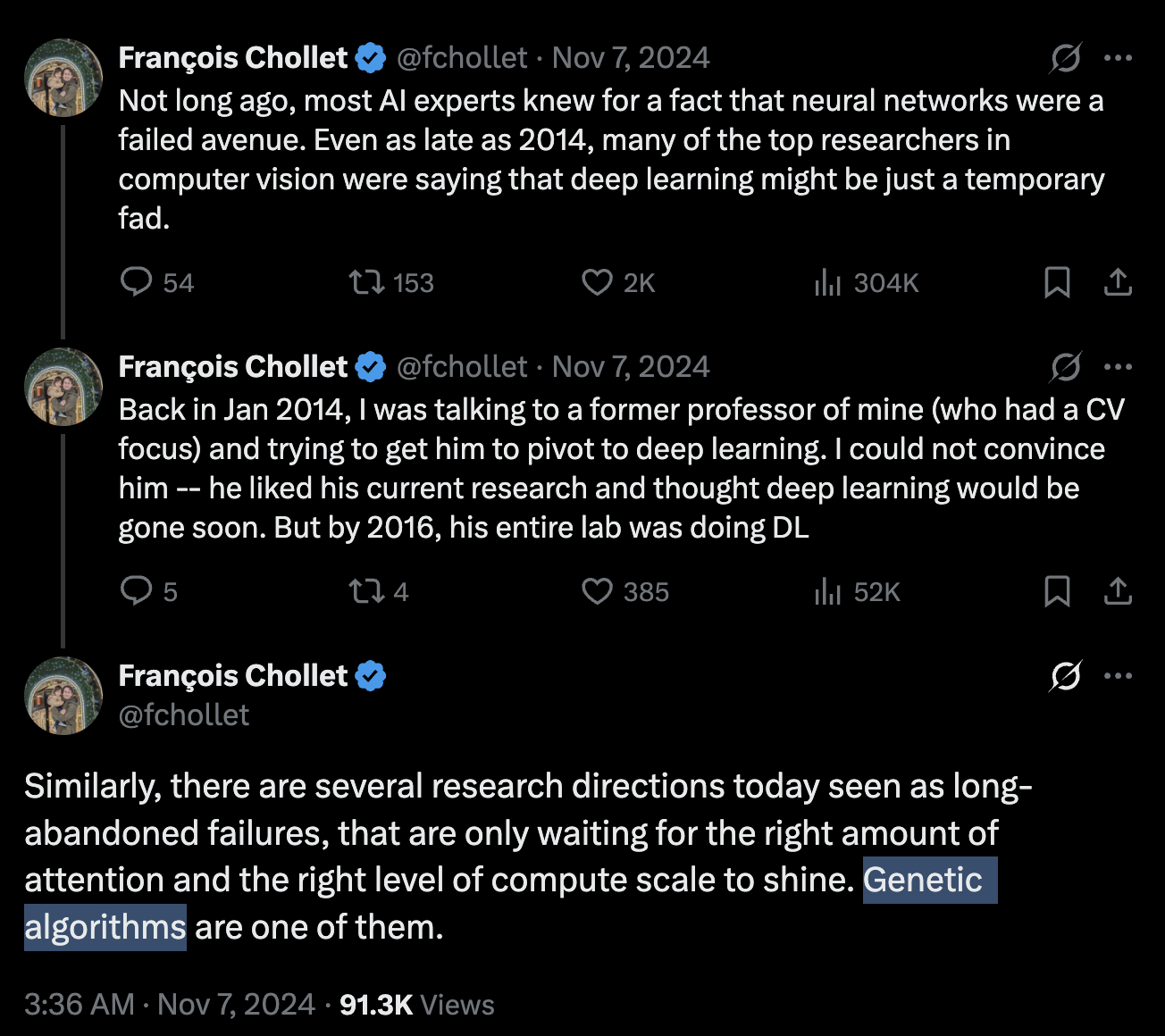 - ref
- ref
At its core, most of AI is about search: navigating vast parameter spaces to minimize a loss function. Deep learning (DL) does this via gradients, while genetic algorithms (GAs) mimic natural evolution—maintaining populations of solutions, breeding the fittest, and introducing mutations.
In this post, we'll explore the analogies between DL and GAs, how GAs can fill the weaknesses of DL, and some applications combining the two.
Spoilers: 1. ![[LLM-driven Genetic Programming Thread by @fchollet (archived)#^d71cc4]] 2. AlphaEvolve A Gemini-powered coding agent for designing advanced algorithms (archived)
Deep learning -> find the best weight values to minimize a loss function f(x ) (for many values of x).
Genetic algorithms -> find the best DNA values to minimize a loss function f(x) (for many values of x).
The way they differ is how they reach to "best" values of weights or DNA.
DL keeps only a single set of weights. At each iteration, updates them by gradients.
GL keeps multiple set of DNA values at the same time. At each iteration, updates them by crossovers and mutatations.
Analogies
iterations - DL and GA both reach at solution through iterations (number of steps vs generations) f - DL has a single f: x->y function at a time, where f is defined by its network weights - GL has multiple versions of f(x) at a time, where each f is defined by DNA values. forward pass - DL does a forward pass to predict f(x) - GL does multiple forward passes (fitness scoring) for each of its f's update mechanism - DL calculates the error for its weights and then calculates gradients by backpropagation, and then update its weights by those gradients - GL calculates the error for each of its f's and then keep the succesfull ones the same, and update some others by recombininations and/or mutatations. The process of killing some of the population and giving births from recombininations from the fittest ones is akin to updating their "weights" with the values of better weights.
Analogy table
| Deep Learning | Genetic Algorithms |
|---|---|
| Weights | DNA / Genome |
| Forward pass | Fitness scoring |
| Backprop (update) | Crossover & mutation updates |
| Training steps | Generations |
| Deep Learning Component | Genetic Algorithm Equivalent | Explanation |
|---|---|---|
| Weights | DNA/Genome | Core parameters encoding the model/solution. |
| Forward Pass | Fitness Scoring | Evaluate how well the current parameters perform on data. |
| Backpropagation & Gradient Update | Crossover & Mutation | Mechanism to refine parameters: precise math vs. stochastic evolution. |
| Training Epochs | Generations | Iterative steps toward optimization. |
| Loss Function (e.g., Cross-Entropy) | Fitness Function (e.g., Accuracy) | Metric to minimize (or maximize, inverted). Lower loss ≈ higher fitness. |
Deep learning minimal main code ```python LR = 0.05 # learning rate for epoch in range(200): # Forward z1 = X @ W1 + b1 # (N,H) a1 = np.maximum(z1, 0) # ReLU z2 = a1 @ W2 + b2 # (N,C) z2 -= z2.max(1, keepdims=True) # stability exp = np.exp(z2) probs = exp / exp.sum(1, keepdims=True) # softmax (N,C)
# Loss calculation (cross-entropy)
loglik = -np.log(probs[np.arange(N), y] + 1e-12)
loss = loglik.mean()
# Backpropagation (calculate gradients)
Y = np.zeros_like(probs)
Y[np.arange(N), y] = 1
dz2 = (probs - Y) / N # (N,C)
dW2 = a1.T @ dz2
db2 = dz2.sum(0, keepdims=True)
da1 = dz2 @ W2.T
dz1 = da1 * (z1 > 0) # ReLU grad
dW1 = X.T @ dz1
db1 = dz1.sum(0, keepdims=True)
# Update weights (by gradients)
W1 -= LR * dW1; b1 -= LR * db1
W2 -= LR * dW2; b2 -= LR * db2
Genetic algorithm minimal main code
```python
MUT_RATE = 0.1 # mutation rate
def fitness(dna): # can be thought as analogous to cross-entropy in DL
...
for generation in range(200):
# "Forward": evaluate all individuals
fit = np.array([fitness(dna) for dna in pop])
# Loss calculation
loss = 1 - fit.mean() # just for analogy
# "Selection": pick survivors
idx = fit.argsort()[::-1][:POP//2]
survivors = pop[idx]
# "Crossover + Mutation": create new children
children = []
while len(children) < POP - len(survivors):
p1, p2 = rng.choice(survivors, 2)
cut = rng.integers(1, DNA)
child = np.concatenate([p1[:cut], p2[cut:]])
mut_mask = rng.random(DNA) < MUT_RATE
child[mut_mask] += rng.normal(0, 0.5, mut_mask.sum())
children.append(child)
# "Update": new generation
pop = np.vstack([survivors] + children)
Analogy to DL loop
Forward pass (DL):
X @ W + b … softmax
GA equivalent: evaluate fitness of each DNA withfitness(dna)Loss (DL): cross-entropy
GA equivalent:1 - accuracy(so “lower loss” ↔ “higher fitness”)Backward (DL): backpropagation chain rule
GA equivalent: selection + crossover + mutation (search operators)Update step (DL):
W -= lr * dW
GA equivalent: replace old population with survivors + children
This way, you can line them up and see: - Both have epochs. - Both evaluate the “current state” (forward vs fitness). - Both change parameters (gradient vs evolutionary operators).
LLM + GA hybrids
ArcAGI best solutions
@jeremy-bermanarc-agi on Params (archived)
AlphaEvolve of DeepMind
![[AlphaEvolve A Gemini-powered coding agent for designing advanced algorithms (archived)#^fc212f]]
AlphaEvolve combines LLMs with genetic search to discover and optimize math algorithms.
Core Principles
- Search Space as Population: Treat algorithms as evolvable "organisms" encoded in code (e.g., Python or Verilog functions).
- Fitness via Objective Metrics: Define success by quantifiable evaluators (accuracy, speed, resource use).
- Variation via LLMs: Leverage Gemini models (Flash for broad ideation, Pro for deep insights) to mutate/crossbreed code, amplifying diversity beyond random tweaks.
- Selection and Iteration: Mimic natural evolution: score, rank, propagate top performers to breed superior offspring, converging on optima over generations.
Components
- LLMs (Gemini Ensemble): Generate and refine code proposals. Flash handles volume/diversity; Pro adds precision/complexity.
- Prompt Sampler: Assembles inputs for LLMs, incorporating problem specs, prior programs, and feedback.
- Automated Evaluators: Verify, execute, and score code on metrics (e.g., runtime, correctness on test cases).
- Programs Database: Stores population; implements evolution by selecting/feeding high-scorers back into prompts.
Algorithm Steps
-
Initialization:
- Seed initial population: Prompt LLMs with problem description to generate diverse code variants (e.g., matrix multiplication kernels).
- Population size: Implicitly managed by database, starting small and growing via iterations.
-
Evaluation:
- For each program: Run evaluators to compute fitness score (e.g., speedup percentage, error rate). Reject invalid code.
-
Selection:
- Rank programs by fitness.
- Elitism: Retain top performers (e.g., highest-scoring 20-50%) as "parents" for next generation.
- Criteria: Thresholds on metrics like min accuracy or max runtime.
-
Variation:
- Mutation: LLM-guided edits to parent code. Examples: Alter optimizer, weights, loss functions, or hyperparameters. Can require chained mutations (e.g., 15 sequential changes for matrix ops). Not random—LLMs propose targeted tweaks based on prompts like "Improve this code's efficiency by modifying X."
- Crossover: Combine elements from multiple parents (e.g., merge function from A with loop from B). LLM-executed: Prompt models to synthesize hybrids, ensuring syntactic validity.
- Output: New offspring programs.
-
Iteration:
- Feed varied offspring back into database.
- Update prompts with evolved programs (e.g., "Build on this top solution").
- Repeat 2-4 until convergence (e.g., no improvement over N generations) or budget exhaust.
-
Termination and Output:
- Extract best program(s): Human-readable, deployable code.
- Examples: 23% faster matrix multiply (shaving 1% off Gemini training), 32.5% speedup for FlashAttention, new math bounds (e.g., 48 ops for 4x4 complex matrices). ##### Pseudocode ```python population = LLMgenerateinitialprograms(problemprompt)
while not converged(population): scores = evaluate(population) # Automated metrics parents = selecttop(scores) # Rank and filter offspring = [] for parent in parents: mutants = LLMmutate(parent) # e.g., 15 chained edits cross = LLM_crossover(parents) # Synthesize hybrids offspring += mutants + cross population = parents + offspring # Elitism + new gen best = max(population, key=scores) return best ```
This yields breakthroughs in verifiable domains (math proofs, hardware design) by scaling compute over generations, outperforming solo LLMs (plateau on ideas) or pure evolution (lacks creativity). Limitations: Relies on strong evaluators; compute-intensive for non-parallelizable tasks.
Neuroevolution of Augmenting Topologies (NEAT)
https://en.wikipedia.org/wiki/Neuroevolution_of_augmenting_topologies - ARC-AGI best solution used it @jeremy-bermanarc-agi on Params (archived)
Appendices
Appendix A: Francois Chollet on genetic search
![[François Chollet on Deep Learning and the Meaning of Intelligence – Sean Carroll (archived)#^9519b6]]
![[Genetic Search Thread by @fchollet (archived)#^318548]]
![[Evolution Intelligence Thread by @fchollet (archived)#^793351]]
Appendix B: Deep learning runnable code
import numpy as np
rng = np.random.default_rng(0)
# ----- Data: XOR blobs ------------------------------------------------------
def xor_blobs(n=200, s=0.4):
centers = np.array([-1,-1],[+1,+1],[-1,+1],[+1,-1](/dead), float)
X = np.vstack([rng.normal(c, s, size=(n//4, 2)) for c in centers])
y = np.repeat([0,0,1,1], n//4)
idx = rng.permutation(n)
return X[idx], y[idx]
X, y = xor_blobs(1000)
N, D, H, C = len(X), 2, 16, 2 # input=2, hidden=16, output=2
# ----- Parameters (Glorot init) ---------------------------------------------
W1 = rng.standard_normal((D,H)) * np.sqrt(2/(D+H))
b1 = np.zeros((1,H))
W2 = rng.standard_normal((H,C)) * np.sqrt(2/(H+C))
b2 = np.zeros((1,C))
# ----- Training loop --------------------------------------------------------
lr = 0.05
for epoch in range(200):
# Forward
z1 = X @ W1 + b1 # (N,H)
a1 = np.maximum(z1, 0) # ReLU
z2 = a1 @ W2 + b2 # (N,C)
z2 -= z2.max(1, keepdims=True) # stability
exp = np.exp(z2)
probs = exp / exp.sum(1, keepdims=True) # softmax (N,C)
# Loss (cross-entropy)
loglik = -np.log(probs[np.arange(N), y] + 1e-12)
loss = loglik.mean()
# Backward
Y = np.zeros_like(probs)
Y[np.arange(N), y] = 1
dz2 = (probs - Y) / N # (N,C)
dW2 = a1.T @ dz2
db2 = dz2.sum(0, keepdims=True)
da1 = dz2 @ W2.T
dz1 = da1 * (z1 > 0) # ReLU grad
dW1 = X.T @ dz1
db1 = dz1.sum(0, keepdims=True)
# Gradient step
W1 -= lr * dW1; b1 -= lr * db1
W2 -= lr * dW2; b2 -= lr * db2
if epoch % 20 == 0:
pred = probs.argmax(1)
acc = (pred == y).mean()
print(f"epoch {epoch:3d} | loss {loss:.3f} | acc {acc:.3f}")
# Final accuracy
print("final acc:", (probs.argmax(1) == y).mean())
Appendix C: Genetic algorithm runnable code
"""
Minimal Genetic Algorithm (GA) — written like DL training loop
---------------------------------------------------------------
- Loop: for epoch in range(...)
- Instead of forward/backward/gradient, we have:
* Evaluate fitness
* Select parents
* Crossover
* Mutation
"""
import numpy as np
rng = np.random.default_rng(0)
# --- Data: XOR blobs --------------------------------------------------------
def xor_blobs(n=200, s=0.4):
centers = np.array([-1,-1],[+1,+1],[-1,+1],[+1,-1](/dead), float)
X = np.vstack([rng.normal(c, s, size=(n//4, 2)) for c in centers])
y = np.repeat([0,0,1,1], n//4)
idx = rng.permutation(n)
return X[idx], y[idx]
X, y = xor_blobs(200)
N, D, C = len(X), 2, 2
DNA = D*C + C # linear model: W (2x2) + b (2,)
# --- GA parameters ----------------------------------------------------------
POP = 50
MUT_RATE = 0.1
GENS = 50
def decode(dna):
W = dna[:D*C].reshape(D, C)
b = dna[D*C:].reshape(1, C)
return W, b
def fitness(dna):
W, b = decode(dna)
logits = X @ W + b
preds = logits.argmax(1)
return (preds == y).mean()
# --- Init population --------------------------------------------------------
pop = rng.standard_normal((POP, DNA))
# --- Training loop (GA style) -----------------------------------------------
for epoch in range(GENS):
# "Forward": evaluate all individuals
fit = np.array([fitness(dna) for dna in pop])
loss = 1 - fit.mean() # just for analogy
# "Selection": pick survivors
idx = fit.argsort()[::-1][:POP//2]
survivors = pop[idx]
# "Crossover + Mutation": create new children
children = []
while len(children) < POP - len(survivors):
p1, p2 = rng.choice(survivors, 2)
cut = rng.integers(1, DNA)
child = np.concatenate([p1[:cut], p2[cut:]])
mut_mask = rng.random(DNA) < MUT_RATE
child[mut_mask] += rng.normal(0, 0.5, mut_mask.sum())
children.append(child)
# "Update": new generation
pop = np.vstack([survivors] + children)
if epoch % 5 <mark> 0 or epoch </mark> GENS-1:
print(f"epoch {epoch:3d} | loss {loss:.3f} | best acc {fit.max():.3f}")
Appendix D: AlphaEvolve sketch
https://grok.com/share/bGVnYWN5_71f0441f-512b-4e0a-b969-a99e63ee4b69 ```python import random from deap import base, creator, tools
Assumptions:
- llm(prompt: str) -> str: Uses a language model to generate or modify code based on the prompt.
- algorithm_evaluate(code: str) -> float: Evaluates the code and returns a fitness score (higher is better).
These functions are assumed to be implemented elsewhere, handling details like code execution safety and metrics.
Create DEAP classes for fitness and individuals.
creator.create("FitnessMax", base.Fitness, weights=(1.0,)) creator.create("Individual", object, fitness=creator.FitnessMax)
def createindividual(problemdescription): """Create a new individual with initial code generated by LLM.""" ind = creator.Individual() prompt = f"Write elegant Python code to solve the following problem: {problem_description}" ind.code = llm(prompt) return ind
def evaluateindividual(individual): """Evaluate the fitness of an individual.""" return (algorithmevaluate(individual.code),)
def mutateindividual(individual, mutationprob=0.8): """Mutate the individual's code using LLM.""" if random.random() < mutation_prob: prompt = ( f"Improve or vary this code while keeping it correct and efficient: \n" f"{individual.code}\n" f"Focus on making meaningful changes inspired by evolutionary principles like adding complexity where beneficial." ) individual.code = llm(prompt) return individual,
def crossoverindividuals(ind1, ind2): """Crossover two individuals' code using LLM to combine them.""" prompt = ( f"Combine the best aspects of these two code snippets into one improved version: \n" f"Code 1: {ind1.code}\n" f"Code 2: {ind2.code}\n" f"Ensure the result is a coherent, functional program." ) combinedcode = llm(prompt) # To produce two offspring, create a slight variation for the second. ind1.code = combinedcode promptvariation = prompt + "\nGenerate a slight variation of the combined code." ind2.code = llm(prompt_variation) return ind1, ind2
def alphaevolve(problemdescription, populationsize=50, generations=20, cxprob=0.5, mut_prob=0.2): """ AlphaEvolve: An LLM-powered evolutionary algorithm for designing advanced algorithms.
Inspired by NEAT's complexification and speciation (though simplified here) and AlphaEvolve's use of LLMs
for code generation and improvement. Evolves code representations using genetic operators assisted by LLMs.
Parameters:
- problem_description: str - Description of the problem to solve (e.g., "implement an efficient sorting network for 4 elements").
- population_size: int - Number of individuals in the population.
- generations: int - Number of generations to evolve.
- cx_prob: float - Probability of crossover.
- mut_prob: float - Probability of mutation (per individual).
Returns:
- best_code: str - The code of the best evolved individual.
"""
toolbox = base.Toolbox()
# Register DEAP functions.
toolbox.register("individual", create_individual, problem_description)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
toolbox.register("evaluate", evaluate_individual)
toolbox.register("mate", crossover_individuals)
toolbox.register("mutate", mutate_individual, mutation_prob=0.9) # High mutation prob for LLM variability.
toolbox.register("select", tools.selTournament, tournsize=3)
# Initialize population.
population = toolbox.population(n=population_size)
fitnesses = list(map(toolbox.evaluate, population))
for ind, fit in zip(population, fitnesses):
ind.fitness.values = fit
# Evolution loop.
for gen in range(generations):
# Select offspring.
offspring = toolbox.select(population, len(population))
offspring = list(map(toolbox.clone, offspring))
# Apply crossover and mutation.
for child1, child2 in zip(offspring[::2], offspring[1::2]):
if random.random() < cx_prob:
toolbox.mate(child1, child2)
del child1.fitness.values
del child2.fitness.values
for mutant in offspring:
if random.random() < mut_prob:
toolbox.mutate(mutant)
del mutant.fitness.values
# Evaluate invalid fitnesses.
invalid_ind = [ind for ind in offspring if not ind.fitness.valid]
fitnesses = map(toolbox.evaluate, invalid_ind)
for ind, fit in zip(invalid_ind, fitnesses):
ind.fitness.values = fit
# Replace population.
population[:] = offspring
# Log best in generation (optional, for monitoring).
best = tools.selBest(population, 1)[0]
print(f"Generation {gen}: Best fitness = {best.fitness.values[0]}")
# Return the best individual's code.
best_individual = tools.selBest(population, 1)[0]
return best_individual.code
Example usage (commented out, as it requires llm and algorithm_evaluate):
problem = "discover an efficient matrix multiplication algorithm for 4x4 matrices"
bestcode = alphaevolve(problem)
print("Best evolved code:\n", best_code)
### Appendix E: GA strategies over fundamentals
Beyond the basic genetic algorithm framework, numerous sophisticated strategies have been developed to enhance performance, diversity, and convergence:
##### Population Structure & Diversity
- [Multi-islands](/unpublished) - Parallel populations with periodic migration
- **Niching & Speciation** - Maintain diverse subpopulations in different regions of search space
- **Crowding** - Replace similar individuals to preserve diversity
- **Fitness Sharing** - Reduce fitness of individuals in crowded regions
- **Cellular GA** - Individuals arranged in spatial grid, breed only with neighbors
##### Selection Strategies
- **Tournament Selection** - Random subsets compete, winner selected
- **Rank-Based Selection** - Select based on rank rather than raw fitness
- **Boltzmann Selection** - Temperature-controlled probabilistic selection
- **Steady-State GA** - Replace few individuals per generation vs. generational replacement
- **Elitism** - Always preserve best individuals across generations
##### Crossover Variants
- **Uniform Crossover** - Each gene independently chosen from either parent
- **Multi-Point Crossover** - Multiple crossover points vs. single-point
- **Order Crossover (OX)** - For permutation problems (TSP, scheduling)
- **Partially Mapped Crossover (PMX)** - Another permutation-preserving operator
- **Arithmetic Crossover** - Weighted average of parent values
- **Simulated Binary Crossover (SBX)** - Mimics single-point for real values
##### Mutation Techniques
- **Gaussian Mutation** - Add normally distributed noise
- **Polynomial Mutation** - Bounded perturbation with controllable distribution
- **Swap Mutation** - Exchange positions (for permutations)
- **Inversion Mutation** - Reverse subsequence
- **Scramble Mutation** - Randomly reorder subsequence
- **Adaptive Mutation** - Adjust mutation rate based on population diversity
##### Advanced Evolutionary Strategies
- **Coevolution** - Multiple populations evolve together (competitive/cooperative)
- **Memetic Algorithms** - Hybrid GA + local search (Lamarckian evolution)
- **Differential Evolution** - Vector differences drive mutation
- **Particle Swarm Optimization** - Social learning from neighborhood bests
- **Estimation of Distribution Algorithms (EDA)** - Learn probability models of good solutions
- **Genetic Programming** - Evolve program trees/graphs, not just parameters
##### Adaptive & Self-Organizing
- **Self-Adaptive GA** - Evolution controls its own parameters (mutation rates, crossover probability)
- **Meta-GA** - GA optimizes GA parameters
- **Hyperheuristics** - Evolve heuristic selection strategies
- **Dynamic Parameter Control** - Adjust operators based on search progress
##### Parallel & Distributed
- **Master-Slave Parallelization** - Distribute fitness evaluation
- **Island Models** - Multiple populations with migration topology
- **Cellular Automata GA** - Local breeding in spatial neighborhoods
- **Hierarchical GA** - Multi-level population structure
##### Problem-Specific Adaptations
- **Constraint Handling** - Penalty methods, repair operators, feasibility rules
- **Multi-Objective GA (MOGA)** - Pareto-optimal solutions (NSGA-II, SPEA2)
- **Dynamic Optimization** - Track moving optima in changing environments
- **Noisy Fitness** - Robust evaluation under uncertainty
- **Large-Scale GA** - Cooperative coevolution for high-dimensional problems